今日头条首次改进DQN网络,解决推荐中的在线广告投放问题

【导读】本文主要介绍今日头条推出的强化学习应用在推荐的最新论文[1],首次改进DQN网络解决推荐中的在线广告投放问题。
背景介绍
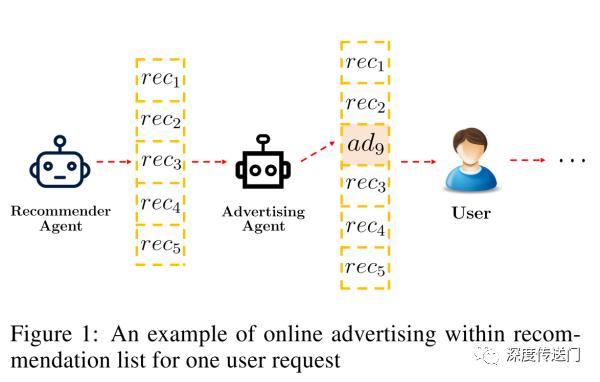
随着最近RL研究的火热,在推荐平台上在线广告投放策略中如何利用RL引起了大家极大的兴趣。然而,大部分基于RL的在线广告投放算法只聚焦于如何使广告收益最大化,却忽略了广告对推荐列表的用户体验可能会带来的负面影响。在推荐列表中不适当地插入广告或者插入广告太频繁都会损害推荐列表的用户体验,与此同时插入太少的广告又会减少广告收入。
因此本文提出了一种全新的广告投放策略来平衡推荐用户体验以及广告的收入。在给定推荐列表前提下,本文提出了一种基于DQN的创新架构来同时解决三个任务:是否插入广告;如果插入,插入哪一条广告;以及插入广告在推荐列表的哪个位置。实验也在某短视频平台上验证了本文算法的效果。
DQN架构
在深入本文具体的算法架构前,我们先来简单回顾下DQN的两种经典结构:
图a的DQN接受的输入是state,输出是所有可能action对应的Q-value;图b的DQN接受的输入是state以及某一个action,输出是对应的Q-value。这两种经典架构的最主要的问题是只能将action定义为插入哪一条广告,或者插入广告在列表的哪个位置,无法同时解决上述提到的三个任务。
当然,从某种程度上来说将插入位置与插入哪一条广告通过某种表示形式譬如one-hot编码来建模action是一种使用上述经典DQN的方式,这样的话action的空间会变成O(A*L),其中A是广告的空间,L是插入列表的位置空间。这样的复杂度对于实际线上的广告系统是不太能够接受的。
改进的DEAR架构
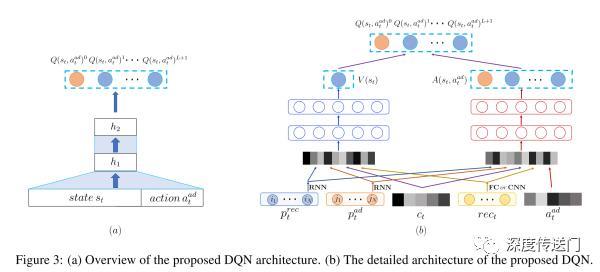
因此,本文提出了一种改进的DQN框架DEAR用来解决上述推荐系统中在线广告投放问题。该框架试图同时解决上述提到的三个任务。也就是说,本框架会同时针对所有可能的插入位置的Q-value进行预估。
如下左图所示,其实是融合了上述提到了两种经典DQN结构的结合,输入层包含State以及Action(插入哪条广告),输出层则是广告插入推荐列表的L+1位置对应的Q-value(假设推荐列表长度为L,则可以插入广告的位置为L+1种可能)。与此同时,使用一个特殊插入位置0用来表示不进行广告插入,因此输出层的长度扩展成为L+2。
DEAR框架详细的架构如下右图所示,输出层Q函数被拆解成两部分:只由state决定的V函数;以及由state和action同时决定的A函数。其中,
state包含了使用GRU针对推荐列表和广告进行用户序列偏好建模的p;当前用户请求的上下文信息c;以及当前请求展示的推荐列表item的特征进行拼接转换形成的低维稠密向量rec;action则包含两部分:一部分是候选插入广告ad的特征;另一部分则是广告插入的位置;其中这里的前半部分会被当做输入层。
reward函数。Reward函数也包含两部分:一部分是广告的的收入r^ad;另一部分则是用户是否继续往下刷的奖励。基于下图的reward函数,最优的Q函数策略便可以通过Bellman等式求得。
Off-Policy训练
本文基于用户交互历史的离线日志,采用 Off-policy的方式进行训练得到最优的投放策略。如下图所示,针对每一次迭代训练:
(第6行)针对用户请求构建state;(第7行)根据标准的off-policy执行action,也就是选取特定ad;(第8行)根据设计好的reward函数,计算reward;(第10行)将状态转移信息(s_t,a_t,r_t,s_t+1)存储到replay buffer;(第11行)从replay buffer中取出mini-batch的状态转移信息,来训练得到最优的Q函数参数。

实验
由于没有同时包含推荐列表和广告item的公开数据集,本文基于从某短视频网站获取的自2019年3月的数据集训练得到模型,该数据集包含两种视频:正常推荐列表的视频和广告视频。正常视频的特征包含:id、点赞数、播放完成率、评论数等;广告视频的特征包含:id、图片大小、定价等。
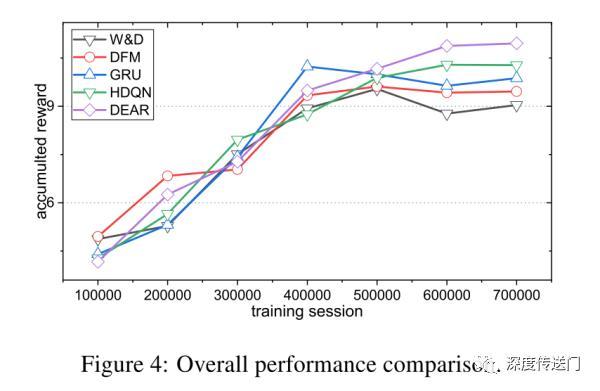
实验对比上本文主要挑选了如下的几个代表性的baseline进行效果对比,为了实验对比的公正性,所有对比算法使用的特征完全一致。
W&D。本文稍微针对W&D进行了扩展来预估是否插入广告以及预估插入广告的CTR。DFM。DeepFM是在W&D基础上改进而来的一种可以额外学习特征间低阶交互的一种架构。本文的实验也表明DFM的表现好于W&D。GRU。GRU4Rec使用GRU来建模用户的历史行为针对用户是否点击进行预估,本文同样也进行了扩展支持实验场景。本文的实验表明GRU4Rec效果好于W&D和DFM。HDQN。HQN是一个层级DQN结构,高阶DQN决定插入位置;低阶DQN选择特定ad进行插入。本文的实验表明HDQN效果好于GRU,因为GRU只是最大化当前请求的immediate奖励,而HDQN则是最大化长期收益。DEAR。本文提出的DEAR框架效果好于HDQN,因为层级的RL架构在使用off-policy方式进行联合训练时有稳定性问题。详细的效果对比,如下图所示。